
標題: [硬件] What comes after Piledriver? [打印本頁]
作者: Puff 時間: 2012-4-14 22:12 標題: What comes after Piledriver?
Kaveri 同 Kabini 果代 APU,係 Fusion Architecture 有 substantial changes 就鉆板上既事啦。
有興趣猜燈謎既話,謎面係 2P。請自便。雖然謎底岩唔岩我都唔 sure,不過鐘意估就估下啦,當買半年後 Fusion12 先開既六合彩。
其實仲有 D 好有趣既 rumor,例如 Charlie 曾經 imply 過 Kaveri is not that bandwidth constrained. 大家各自演譯啦。

要估 Steamroller 有乜變動又係一件難事。不過數下手指都係 AMD 庶出大皇子後宮初現世三年後既產物,大概應該唔會太差掛。
至少應該做得儲君啦?

引用:
after Piledriver, there will be substantial changes in both cores and system architecture from Steamroller onwards, that should help make AMD competitive closer to the top.
[ 本帖最後由 Puff 於 2012-4-14 22:25 編輯 ]
作者: cheungmanhoi 時間: 2012-4-14 23:45
好複雜
作者: qcmadness 時間: 2012-4-15 00:30
throughput =/= real world performance
作者: Puff 時間: 2012-4-15 02:07
引用:
原帖由 qcmadness 於 2012-4-15 00:30 發表 
throughput =/= real world performance
作者: qcmadness 時間: 2012-4-15 02:25
引用:
原帖由 Puff 於 2012-4-15 02:07 發表
Errr... Did I mention anything related to throughput?
作者: Puff 時間: 2012-4-15 13:28
引用:
原帖由 qcmadness 於 2012-4-15 02:25 發表
bandwidth主要影響real world, 唔太影響throughput (theoretical max)
作者: qcmadness 時間: 2012-4-15 13:28
引用:
原帖由 Puff 於 2012-4-15 13:28 發表
Yep. 果句係 reply 緊 graphics/3D (real world) performance.
作者: Puff 時間: 2012-4-15 13:29
引用:
原帖由 qcmadness 於 2012-4-15 13:28 發表
no, cpu都係
作者: Puff 時間: 2012-4-15 17:21
算啦,反正都係估,講埋出黎啦。
Speculation of Future Fusion Architecture... Kaveri/Kabini: (First Gen of HSA compatible APU...)

1. Unified Virtual Address Space
2. Memory Coherence = GPU and CPU access the same piece of memory with the same address
3. Unified Phyiscal Address Space with NUMA (as GPU can access all system memory and page fault)

4. x86 pointer will work for GPU = GPU uses x86 page tables...
5. Can over allocate memory... = (3) + NUMA memory management
6. GPU will page fault = GPU will syscall CPU for OS page fault handling = Graphics memory can access and managed by OS...
http://www.lanl.gov/orgs/hpc/salishan/salishan2011/3moore.pdf
7. P.5 Stacked Memory & Main Memory Co-existing
雖然話係 Concept represents engineering capability only,不過畫得出黎就大概有諗過或者打算要做啦。
8. P.7 Single unified & coherent address space
... Conclusion of this piece of crap
= CPU + GPU working together in a seamless, unified memory. Allocate memory like a NUMA system (?)
+ GDDR5 memory on package (???) GDDR5 memory can access by both CPU and GPU using the same address. Managed by OS (??)
+ Limited Cache Coherency between CPU and GPU??*
+ Large Capacity System Memory vs High-bandwidth GDDR5 memory (will be replaced by Stacked Memory). (??)
+ Discrete GPU 經 Coherent PCIe 玩埋一份 (之前 HSA roadmap 有 Coherent PCIe 架)
應該無用到乜敏感名詞掛,嗯。地氈地捕料捕左幾個月,綜合出黎既野全部吐嘔晒出黎啦。跟往落黎等 Fusion12 六合彩開彩。
GDDR5 memory on package 就真係無乜根據既,based on 個人幻想、Point (7) 同埋 rumours 黎估架咋。
* Wild Guess: 如果所有 GPU access 都要 probe CPU cache 就真係弊傢伙. 大概只會得 GPU access to system memory 先會 probe CPU cache 掛。換句話講,access could be unsafe if the piece of memory (in graphics memory) is shared between CPU and GPU.
[ 本帖最後由 Puff 於 2012-4-15 17:53 編輯 ]
作者: XT 時間: 2012-4-15 18:13
GPU support C , C++ 係乜意思?
作者: Puff 時間: 2012-4-15 18:55
引用:
原帖由 XT 於 2012-4-15 18:13 發表
GPU support C , C++ 係乜意思?
目前大部份既 GPU 只可以跑 Shader Assembly/IL (HLSL, GLSL, Cg, IL...) 同埋 Modified 既高階語言。比如話 OpenCL C 或者 CUDA C 之類。除左 Modified Language 外都有 Library,例如 C++ AMP。但 C++ AMP 都有 restriction,唔係全部 C++ syntax 呀 features 呀都可以用。
換句話講,GPU 將會十卜所有高階語言所需要既 hardware features。
[ 本帖最後由 Puff 於 2012-4-15 18:58 編輯 ]
作者: qcmadness 時間: 2012-4-15 18:58
引用:
原帖由 Puff 於 2012-4-15 18:55 發表
GPU 可以直接跑由 Standard C/C++ Code。
目前大部份既 GPU 只可以跑 Shader Assembly/IL (HLSL, GLSL, Cg, IL...) 同埋 Modified 既高階語言。比如話 OpenCL C 或者 CUDA C 之類。除左 Modified Language 外都有 ...
作者: Puff 時間: 2012-4-15 18:59
引用:
原帖由 qcmadness 於 2012-4-15 18:58 發表
that will become power inefficient
[ 本帖最後由 Puff 於 2012-4-15 19:03 編輯 ]
作者: qcmadness 時間: 2012-4-15 19:03
引用:
原帖由 Puff 於 2012-4-15 18:59 發表
How come? Coding with the same full set of language features doesn't mean that you code them together.
x86比ARM曬電的主要係legacy野太多
作者: Puff 時間: 2012-4-15 19:06
引用:
原帖由 qcmadness 於 2012-4-15 19:03 發表
愈要power efficient, 就愈要support少d instruction set
x86比ARM曬電的主要係legacy野太多
[ 本帖最後由 Puff 於 2012-4-15 19:07 編輯 ]
作者: qcmadness 時間: 2012-4-15 19:06
引用:
原帖由 Puff 於 2012-4-15 19:06 發表
Paging, Syscall 同埋 Virtual Function 咋喎。Target ISA 都已經唔同。
作者: Puff 時間: 2012-4-15 19:10
引用:
原帖由 qcmadness 於 2012-4-15 19:06 發表
virtual function... 已經夠你麻煩
[ 本帖最後由 Puff 於 2012-4-15 19:12 編輯 ]
作者: qcmadness 時間: 2012-4-15 19:12
引用:
原帖由 Puff 於 2012-4-15 19:10 發表
但我唔覺得同 power efficiency 有關係,同 execution time 有關姐。換句話講,x86 同 ARM 咪又係一樣 support standard C/C++.
作者: Puff 時間: 2012-4-15 19:18
引用:
原帖由 qcmadness 於 2012-4-15 19:12 發表
但係同樣transistor的效能差好遠
舉個例 virtual function,麻煩既只係 OOP implementation in assembly. GCN 已經有 Scalar Unit 做 offload。除非你所有 work-item 全部跳唔同 path,咁就真係 extremely inefficient 啦。但呢種 case... 係都用 CPU 跑啦。
作者: qcmadness 時間: 2012-4-15 19:20
引用:
原帖由 Puff 於 2012-4-15 19:18 發表
但我真係覺得唔關事,Support C/C++0x 唔代表 GPU 要支援所有 legacy instructions 或者本來由 CPU run 既 low-level instructions。正如你 malloc 都會係 allocate 完你先開始跑 kernel 一樣咋嘛。
舉個例 virtual ...
作者: Puff 時間: 2012-4-15 19:20
引用:
原帖由 qcmadness 於 2012-4-15 19:20 發表
問題係某2間廠想將所有野用GPU跑
作者: qcmadness 時間: 2012-4-15 19:22
引用:
原帖由 Puff 於 2012-4-15 19:20 發表
一間咋喎。
NVIDIA: GPU兼跑CPU code
Intel: CPU arch當GPU, 行CPU/GPU code
作者: Puff 時間: 2012-4-15 19:25
引用:
原帖由 qcmadness 於 2012-4-15 19:22 發表
2間
NVIDIA: GPU兼跑CPU code
Intel: CPU arch當GPU, 行CPU/GPU code
至於 Nvidia,Nvidia 係想將所有野比 GPU 跑,但佢地係想將絕大部份 normal application 可以 parallelizable 既部份 offload 比 GPU。如果唔係開發 Denver,Echelon 依然有 Latency-optimized Core 係用黎做乜呢。
[ 本帖最後由 Puff 於 2012-4-15 19:28 編輯 ]
作者: qcmadness 時間: 2012-4-15 19:28
引用:
原帖由 Puff 於 2012-4-15 19:25 發表
Intel... Larrabee. Hmmm... 呢個條件符合. 但佢唔係 GPU with CPU ISA,佢係 Many streamlined CPU cores running graphics pipeline,同 AMD/Nvidia 有本質上既分別。GenX Graphics 就係同 Nvidia/AMD 一樣既路。
至 ...
作者: Puff 時間: 2012-4-15 19:30
引用:
原帖由 qcmadness 於 2012-4-15 19:28 發表
所以Intel GPU的問題遠遠比NVIDIA的嚴重...
作者: qcmadness 時間: 2012-4-15 19:32
引用:
原帖由 Puff 於 2012-4-15 19:30 發表
但我講緊 AMD 咋喎
GPU要support既野愈多, 就會愈inefficient
作者: Puff 時間: 2012-4-15 19:36
引用:
原帖由 qcmadness 於 2012-4-15 19:32 發表
AMD其實根本唔好攪咁多呢類野, INT留番比CPU好了
GPU要support既野愈多, 就會愈inefficient
你講果堆 "Integer" Workload,或者話 Low-level System Feature e.g. memory management, I/O transaction GPU 大概唔會做。Syscall CPU 黎做咪得。Page fault 又係 OS 去 handle 既。OS 依然跑在 CPU 上喎。
Integer on GPU 又唔係無用既,好似 X264 呢類 Video Transcoding 咪用得著 Integer @ GPU。

[ 本帖最後由 Puff 於 2012-4-15 19:39 編輯 ]
作者: qcmadness 時間: 2012-4-15 19:39
引用:
原帖由 Puff 於 2012-4-15 19:36 發表
AMD 搞緊既係 Better Programmability on GPU. Virtual Function, Exception Handling, Syscall, x86 Paging Support 諸如此類.
你講果堆 "Integer" Workload,或者話 Low-level System Feature e.g. memory managem ...
作者: Puff 時間: 2012-4-15 19:42
引用:
原帖由 qcmadness 於 2012-4-15 19:39 發表
呢d野都唔駛用GPU做, bulldozer就係設計來CPU handle一部分, GPU handle一部分

GPU 同 CPU integrate 又係一件唔可能既事。
[ 本帖最後由 Puff 於 2012-4-15 19:43 編輯 ]
作者: qcmadness 時間: 2012-4-15 20:01
引用:
原帖由 Puff 於 2012-4-15 19:42 發表
I object. 呢 D 野係 GPU 無得唔做,如果你要跑 standard code as you run on CPU 既話。
GPU 同 CPU integrate 又係一件唔可能既事。
咁會增加latency, 如果唔係為左掉FP俾GPU做, 我諗唔到有咩理由一定要shared FP
http://www.realworldtech.com/page.cfm?ArticleID=RWT082610181333引用:
Like all previous designs from AMD (and in contrast to Intel), Bulldozer separates the integer and floating point schedulers, register files and execution units. In proof that Sutherland’s Wheel of Reincarnation applies to more than just graphics, Bulldozer employs a co-processor model for floating point and SIMD execution that is shared by both cores in a module – reminiscent of the days when x87 floating point co-processors would reside on a separate chip altogether. One advantage of this more formalized separation is that the floating point cluster might eventually be replaced or supplemented by a GPU shader array, an evolution of Bulldozer to fit the ‘Fusion’ mold. This co-processor model is an example of a substantial change that is also familiar from previous AMD CPUs, the resemblance is clear from Figure 4 below.
作者: Puff 時間: 2012-4-15 20:08
Different HW characteristics 就已經注定左 GPU/CU 唔會同 CPU integrate.
Bulldozer 既 Modular Design 同 GPU 都無乜關係... 係關 area/power efficiency & throughput maximizing 既事。
Decoupled INT/FP 都唔係證明,呢個由 K7 至今既設計... 你引 David Kanter 果段只係佢 personal guess.
比如話呢段 pseudo code複製內容到剪貼板
代碼:
load file A from disks to memory location A
do 2048 times, index = idx, start from 0:
load from memory location [A + idx] to register A
add 1 to register A
write to memory location [B + idx] with the value of register A
end於 CPU 角度而言,佢只係一個 I/O transaction 外加一個 Read-execute-write 既 Sequential Loop WITHIN a same thread,唔理佢既 value 係乜。而呢段 Code 既 Program Counter 只得一個,得一條 codepath。係 CPU 上要跑 Vector 就一定係 explict vector.
e.g. add GPR (64-bit Integer) / paddw xmm128 (128-bit Packed Integer) / vpaddw ymm128 (256-bit Packed Integer)
但如果用 CPU + GPU 黎寫,個 pseudo code 就會係複製內容到剪貼板
代碼:
load file A from disks to memory location A
Task on a 32-CU GPU working over 2048 work-items with 64-wide workgroups:
load from memory location [A + getIndex()] to register A
add 1 to register A
write to memory location [B + getIndex()] with the value of register A
end睇落都係一樣,但係呢個 "Task" 事實上係 32 條 64-wide hardware GPU threads 跑係 32 CU 既 GPU 上面。夾埋有 32 個 program counter (32 codepaths) 同埋 32 套 thread state... 外加 Implictly vector 為主. 即係 32 個 Mini Co-processor Cores 咁既樣,但係跑唔同既 ISA...
分別就已經出左黎,以 x86 CPU ISA/Programming Model 唔會做到。
CPU 最多係 control GPU execution,例如話擲一個 high-priority kernel 入去 GPU workgroup queue,GPU 就 context switch 部份 Compute Unit 黎優先執行呢個 high-priority kernel 咁。直接 offload 比 GPU 係唔可能既事。換句話講,GPU 依然要自己 handle branching,自己 syscall,自己 decode 自己既 instructions.
[ 本帖最後由 Puff 於 2012-4-15 20:18 編輯 ]
作者: qcmadness 時間: 2012-4-15 20:16
引用:
原帖由 Puff 於 2012-4-15 20:08 發表
Different HW characteristics 就已經注定左 GPU/CU 唔會同 CPU integrate.
Bulldozer 既 Modular Design 同 GPU 都無乜關係... 係關 area/power efficiency & throughput maximizing 既事。
Decoupled INT/FP 都唔 ...
CPU: check cache hieracy and conflicts > load to L1 cache > execute > write to memory
GPU: load to cache > execute > write to memory
decouple CPU同GPU queue係AMD一貫做法, 但唔係而家的unified scheduler
作者: Puff 時間: 2012-4-15 20:21
引用:
原帖由 qcmadness 於 2012-4-15 20:16 發表
問題係你果堆code對CPU / GPU loading唔同
CPU: check cache hieracy and conflicts > load to L1 cache > execute > write to memory
GPU: load to cache > execute > write to memory
decouple CPU同GPU queue係 ...
你諗下啦,你用一堆 Compute Unit 取代左 Flex FP 之後,請問不論 CPU vector instructions 定 GPU applications 要點 run?
GPU 既 model 係 many hardware threads/wavefronts with many code stream. 基本上每個 CU 自己已經係一個 independent code stream.
CPU 係 sequential/single code stream (SMT 另計). 就算係 Flex FP,佢都係 working for a single code stream,follows a single codepath。
[ 本帖最後由 Puff 於 2012-4-15 20:27 編輯 ]
作者: qcmadness 時間: 2012-4-15 20:27
引用:
原帖由 Puff 於 2012-4-15 20:21 發表
重點唔係 loading 上,而係佢地既 execution model.
你諗下啦,你用一堆 Compute Unit 取代左 Flex FP 之後,請問不論 CPU vector instructions 定 GPU applications 要點 run?
GPU 既 model 係 many hardware threads/wa ...
作者: Puff 時間: 2012-4-15 20:29
引用:
原帖由 qcmadness 於 2012-4-15 20:27 發表
到時會係shared scheduler
Flex FP 或者 CPU 自己既 Vector Unit 唔理你係 Unified Scheduler 定 Decoupled Co-processor Model 都好,都唔可能會被 GPU 取代。
同 bunch of Compute Units 黎取代 Flex FP 就同你將 32 個 CPU Cores 既 execution resources 塞入一個 4-wide 既 Core 一樣。
[ 本帖最後由 Puff 於 2012-4-15 20:30 編輯 ]
作者: qcmadness 時間: 2012-4-15 20:35
引用:
原帖由 Puff 於 2012-4-15 20:29 發表
我唔覺得關 scheduler 事。
Flex FP 或者 CPU 自己既 Vector Unit 唔理你係 Unified Scheduler 定 Decoupled Co-processor Model 都好,都唔可能會被 GPU 取代。
同 bunch of Compute Units 黎取代 Flex FP ...
作者: Puff 時間: 2012-4-15 20:38
http://developer.amd.com/afds/assets/presentations/2901_final.pdf
P.17
其實都唔洗我 explain.引用:
These two approaches suit different algorithm designs. We cannot, unfortunately, have both in a single core
作者: qcmadness 時間: 2012-4-15 20:50
of course, but you can load it in different core or execution units in a silicon
作者: Puff 時間: 2012-4-15 21:25
引用:
原帖由 qcmadness 於 2012-4-15 20:50 發表
of course, but you can load it in different core or execution units in a silicon
[ 本帖最後由 Puff 於 2012-4-15 21:27 編輯 ]
作者: qcmadness 時間: 2012-4-15 21:31
引用:
原帖由 Puff 於 2012-4-15 21:25 發表
總覺得我地講緊既野南轅北轍。乜叫 scheduler? 乜野既 scheduler? Schedule D 乜既 scheduler?
作者: Puff 時間: 2012-4-15 21:32
引用:
原帖由 qcmadness 於 2012-4-15 21:31 發表
use x86 instruction utilize GPU as co-processor
作者: qcmadness 時間: 2012-4-15 21:33
引用:
原帖由 Puff 於 2012-4-15 21:32 發表
咁問題就係呢個 "scheduler" 點運作法,係 pipeline 上乜野位置呀嘛。
作者: Puff 時間: 2012-4-15 21:33
引用:
原帖由 qcmadness 於 2012-4-15 21:33 發表
replace the current FP scheduler and GPU scheduler
作者: qcmadness 時間: 2012-4-15 21:33
引用:
原帖由 Puff 於 2012-4-15 21:33 發表
Okay. Is there any new ISA extension for this?
作者: Puff 時間: 2012-4-15 21:34
引用:
原帖由 qcmadness 於 2012-4-15 21:33 發表
no
作者: qcmadness 時間: 2012-4-15 21:36
引用:
原帖由 Puff 於 2012-4-15 21:34 發表
How would you define a GPU scheduler?

Command processor
作者: Puff 時間: 2012-4-15 21:39
引用:
原帖由 qcmadness 於 2012-4-15 21:36 發表
Command processor
Compute Units 本身就係一個 4- to 40-way something-like SMT 既 "Core" 黎架啦喎。
作者: qcmadness 時間: 2012-4-15 21:40
引用:
原帖由 Puff 於 2012-4-15 21:39 發表
... 你真係覺得可以?
Compute Units 本身就係一個 4- to 40-way SMT 既 "Core" 黎架啦喎。
作者: Puff 時間: 2012-4-15 21:42
引用:
原帖由 qcmadness 於 2012-4-15 21:40 發表
可以, 但係其實VLIW仲好做
每個 Compute Unit 有自已既 Program Counter,可以跑多過一個 kernel program。用呢個龐然大物黎取代 FPU,咁 CPU vector instructions 係 decode 之後要做乜?
作者: qcmadness 時間: 2012-4-15 21:44
引用:
原帖由 Puff 於 2012-4-15 21:42 發表
點做?
每個 Compute Unit 有自已既 Program Counter,可以跑多過一個 kernel program。用呢個龐然大物黎取代 FPU,咁 CPU vector instructions 係 decode 之後要做乜?
HD6970 / 24 => 113 GFlops / shader (800MHz)
SandyBridge 2600K => 8 FP * 3.4 x 10^9 * 4 cores = 108.8 GFLOPs (3400MHz)
作者: Puff 時間: 2012-4-15 21:45
引用:
原帖由 qcmadness 於 2012-4-15 21:44 發表
一組VLIW-4 shader已經可以取代4個core FPU, 你估邊樣efficient d?
16 VLIW-4 Shaders 夾埋既 SIMD Engine 自己本身已經係一個 Fetch, Decode & Execute 既 Core.
CPU 既 FPU... 係 Out-of-order Scheduler + Execution Pipes + Backend 既一個 Unit.
前者係 DLP + TLP, 後者係 ILP + Latency-optimized...
[ 本帖最後由 Puff 於 2012-4-15 21:47 編輯 ]
作者: qcmadness 時間: 2012-4-15 21:49
引用:
原帖由 Puff 於 2012-4-15 21:45 發表
...... 我真係想講兩樣唔同野黎架喎,Efficient 係唔同既地方。
16 VLIW-4 Shaders 夾埋既 SIMD Engine 自己本身已經係一個 Fetch, Decode & Execute 既 Core.
CPU 既 FPU... 係 Out-of-order Scheduler + Execution ...
唔係Intel/AMD一早做到出來啦
作者: Puff 時間: 2012-4-15 21:51
引用:
原帖由 qcmadness 於 2012-4-15 21:49 發表
所以要時間tune到2者融合
唔係Intel/AMD一早做到出來啦
再講,點樣將 CPU 既 FPU instructions translate 做 GPU 既 executable? 如果係 vector + GPR instruction mix 又點?
作者: qcmadness 時間: 2012-4-15 21:52
引用:
原帖由 Puff 於 2012-4-15 21:51 發表
咁你講晒姐,我會歸類做 idealistic 囉。
再講,點樣將 CPU 既 FPU instructions translate 做 GPU 既 executable? 如果係 vector + GPR instruction mix 又點?
都係果句, 要translate唔難, 但係做到hieracy之類仲難, 因為x86既restriction/memory disambiguation多好多
作者: Puff 時間: 2012-4-15 21:54
引用:
原帖由 qcmadness 於 2012-4-15 21:52 發表
如果係idealistic, AMD就唔會買ATi, finish
最後既問題就係 what's the point of doing this. GPU 同 CPU 既 design aim 根本就唔同。
我覺得成件事要從 hardware pipeline 解得通先有 possibility 囉。
作者: qcmadness 時間: 2012-4-15 21:54
引用:
原帖由 Puff 於 2012-4-15 21:54 發表
AMD 買 ATi 都唔代表要整 D 乜鬼 CPU fused together with GPU and they become SuperPU muhahahahah.
最後既問題就係 what's the point of doing this. GPU 同 CPU 既 design aim 根本就唔同。
我覺得成件事要從 ...

作者: Puff 時間: 2012-4-15 21:55
引用:
原帖由 qcmadness 於 2012-4-15 21:54 發表
所以要時間lor, 唔係一早2011年就出左hetergeneous computing啦
但事實上無人咁講過。
Core-level integration 果種喎。
[ 本帖最後由 Puff 於 2012-4-15 21:56 編輯 ]
作者: qcmadness 時間: 2012-4-15 21:59
引用:
原帖由 Puff 於 2012-4-15 21:55 發表
唔關時間既問題事,而係你出發既角度就係 CPU 同 GPU 最終會 Tightly Fuse 埋一齊。
但事實上無人咁講過。
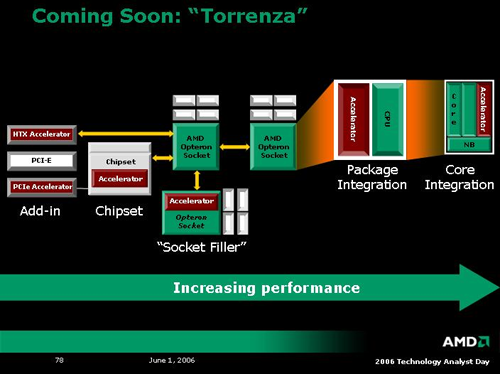
作者: Puff 時間: 2012-4-15 22:00
引用:
原帖由 qcmadness 於 2012-4-15 21:59 發表
作者: qcmadness 時間: 2012-4-15 22:01
引用:
原帖由 Puff 於 2012-4-15 21:55 發表
唔關時間既問題事,而係你出發既角度就係 CPU 同 GPU 最終會 Tightly Fuse 埋一齊。
但事實上無人咁講過。
Core-level integration 果種喎。
引用:
Advanced Micro Devices plans to finally launch its hybrid chips – which feature x86 central processing along with graphics processing cores – code-named Fusion in early 2011, however, according to a vice president of AMD, the second iteration of Fusion processors will not only be heterogeneous in terms of different cores within one piece of silicon, but the cores themselves will process both graphics and general-purpose data.
“The first iteration of Fusion will include a CPU and GPU, but by 2015 the model could change. In the second iteration [in] 2015, you are not going to be able to tell the difference. It's all going away," said Leslie Sobon, vice president of marketing at AMD, reports IDG News agency.
作者: qcmadness 時間: 2012-4-15 22:04
引用:
原帖由 Puff 於 2012-4-15 21:55 發表
唔關時間既問題事,而係你出發既角度就係 CPU 同 GPU 最終會 Tightly Fuse 埋一齊。
但事實上無人咁講過。
Core-level integration 果種喎。


作者: Puff 時間: 2012-4-15 22:04
Marketing.
佢點 Fusion 都係佢既事,我亦都無 object 過 CPU integrate GPU 既 "controller" 既可能性 (或者 ACE kind of thing,as you like)。AMD 都有 Patent 描述過類似既 implementation。我 object 既係 Replace FPU with GPU.
作者: qcmadness 時間: 2012-4-15 22:05
引用:
原帖由 Puff 於 2012-4-15 22:04 發表
Marketing.
佢點 Fusion 都係佢既事,我亦都無 object 過 CPU integrate GPU 既 "controller" 既可能性 (或者 ACE kind of thing,as you like)。AMD 都有 Patent 描述過類似既 implementation。我 object 既係 Replace ...
唔需要external ISA, 用番x86就用到CPU+GPU先係買ATi的價值
要chipset, SiS都做到啦
只係要graphics expert, VIA都做到啦
點解要咁大既ATi?
作者: Puff 時間: 2012-4-15 22:06
引用:
原帖由 qcmadness 於 2012-4-15 22:04 發表
*pics*
Heterogeneous Computing 係 many different kind of cores working together,唔係 fuse all cores together and become one.
作者: Puff 時間: 2012-4-15 22:07
引用:
原帖由 qcmadness 於 2012-4-15 22:05 發表
integrate GPU做fusion, 而家都做到啦
唔需要external ISA, 用番x86就用到CPU+GPU先係買ATi的價值
要chipset, SiS都做到啦
只係要graphics expert, VIA都做到啦
點解要咁大既ATi? ...
作者: qcmadness 時間: 2012-4-15 22:08
引用:
原帖由 Puff 於 2012-4-15 22:06 發表
我睇過,咁點?重點係呢堆 Slides 可以佐證到你講既乜野。
Heterogeneous Computing 係 many different kind of cores working together,唔係 fuse all cores together and become one. ...
你要明白要有效咁用埋GPU, OpenCL都睇得出唔會點流行, 唔merge佢地一齊用係大部分浪費
作者: qcmadness 時間: 2012-4-15 22:09
引用:
原帖由 Puff 於 2012-4-15 22:07 發表
咁請問要 HSA IL 黎做乜?點解要用 x86 跑 GPU?呢個係你個人意見咋喎。
作者: Puff 時間: 2012-4-15 22:12
引用:
原帖由 qcmadness 於 2012-4-15 22:08 發表
咁而家都已經係 (Llano / SandyBridge), 點解仲要evolve?
你要明白要有效咁用埋GPU, OpenCL都睇得出唔會點流行, 唔merge佢地一齊用係大部分浪費
但係同 FPU replace with GPU 無乜關係喎。將 Speedy + Tightly Coupled to CPU pipeline 既 FPU 取代成 Slow + Loosely Coupled to CPU pipeline 既 GPU 係我最唔明白既事,呢兩個本來就係唔同既存在。完全唔同既 execution model.
HSA 既 purpose 就係 main path on CPU, tasks on either CPU and GPU.
You can still run branchy vector code on CPU with the FP unit, and run embarrassingly parallelizable code on GPU.

作者: qcmadness 時間: 2012-4-15 22:15
引用:
原帖由 Puff 於 2012-4-15 22:12 發表
有效地運用 GPU 唔代表要 Merge 埋佢地一齊,OpenCL 流唔流行一件事,HSA 既出現就係為左你所講既野。
但係同 FPU replace with GPU 無乜關係喎。將 Speedy + Tightly Coupled to CPU pipeline 既 FPU 換做 Slow + Loosely Coupled to CPU pipeline ...

FP instruction本身就係high latency, 所以問題無咁大
作者: Puff 時間: 2012-4-15 22:16
引用:
原帖由 qcmadness 於 2012-4-15 22:15 發表
AMD的FPU不嬲都同CPU有少少decoupled, Intel就真係tightly coupled
*pic*
作者: qcmadness 時間: 2012-4-15 22:17
引用:
原帖由 Puff 於 2012-4-15 22:16 發表
佢 decoupled from the integer pipeline,但係依然係 a part of the CPU pipeline. 依然會 handshake with integer core.
如果你記得, K8既pipeline係12 (INT) / 17 (FP) stages
作者: Puff 時間: 2012-4-15 22:17
引用:
原帖由 qcmadness 於 2012-4-15 22:17 發表
其實幾乎唔會, 除左load memory
作者: Puff 時間: 2012-4-15 22:18
引用:
FP instruction本身就係high latency, 所以問題無咁大
作者: qcmadness 時間: 2012-4-15 22:19
引用:
原帖由 Puff 於 2012-4-15 22:17 發表
No. Instruction Retire.
咁易做就唔會要做10年, 包括Intel
作者: qcmadness 時間: 2012-4-15 22:19
引用:
原帖由 Puff 於 2012-4-15 22:18 發表
呢個唔係理由。FP instructions 高極有限,back-to-back 都係 max 6 cycles 最低 2 cycles. Offload 去 GPU 呢?唔計中間一大堆野,GPU 既 frequency 同 CPU 已經有個落差,再加埋 4-cycle back-to-back issue... ...
一個sqrt已經29-38 cycle latency (Family 15h)
作者: Puff 時間: 2012-4-15 22:20
引用:
原帖由 qcmadness 於 2012-4-15 22:19 發表
所以full CPU+GPU fusion要差唔多10年先有
咁易做就唔會要做10年, 包括Intel
[ 本帖最後由 Puff 於 2012-4-15 22:21 編輯 ]
作者: qcmadness 時間: 2012-4-15 22:21
引用:
原帖由 Puff 於 2012-4-15 22:20 發表
... 我已經無野好講,我只可以話係我既角度而言,你執著於 Fusion 呢個字多於現實中既 possibility。
GPU技術唔係NVIDIA / ATi先有
作者: Puff 時間: 2012-4-15 22:24
引用:
原帖由 qcmadness 於 2012-4-15 22:21 發表
如果唔係possibility, 咁AMD唔駛買ATi, 買SiS / VIA都已經夠
GPU技術唔係NVIDIA / ATi先有
AMD 買 ATi 係要搞 AMD Fusion 無錯。呢個係 facts。但我講緊既係 How to Fusion 甚至係 What is Fusion.
[ 本帖最後由 Puff 於 2012-4-15 22:25 編輯 ]
作者: qcmadness 時間: 2012-4-15 22:25
引用:
原帖由 Puff 於 2012-4-15 22:24 發表
Computer Architecture 已經發展左咁耐,框架就得果個,定左型。一件事可唔可行,值唔值得,唔會睇唔出。
AMD 買 ATi 係要做 AMD Fusion 無錯。呢個係 facts。我講緊既係 How to Fusion 甚至係 What is Fusion. ...
作者: qcmadness 時間: 2012-4-15 22:25
引用:
原帖由 Puff 於 2012-4-15 22:24 發表
Computer Architecture 已經發展左咁耐,框架就得果個,定左型。一件事可唔可行,值唔值得,唔會睇唔出。
AMD 買 ATi 係要搞 AMD Fusion 無錯。呢個係 facts。但我講緊既係 How to Fusion 甚至係 What is Fusion. ...
作者: Puff 時間: 2012-4-15 22:30
引用:
原帖由 qcmadness 於 2012-4-15 22:25 發表
用同1個ISA model先最有效率, 唔駛software intercept仲好
8 Big Cores 跑 8 Threads,Speedy Core (3+ Ghz).
32 Small Cores 跑 1280 條 threads,Slow cores (~1 Ghz).
點樣整成 32 Small Cores in 8 Big Cores and Big Cores offload all vector instructions to small cores?
你自己諗下啦,基於 modern CPU architecture 既 acknowledge 再畫下線都解唔通啦。
作者: qcmadness 時間: 2012-4-15 22:32
引用:
原帖由 Puff 於 2012-4-15 22:30 發表
當你 CPU 同 GPU share the same ISA,咪即係
8 Big Cores 跑 8 Threads,Speedy Core (3+ Ghz).
32 Small Cores 跑 1280 條 threads,Slow cores (~1 Ghz).
點樣整成 32 Small Cores in 8 Big Cores and Big Cores of ...
你可以話唔可能, 2002年你會唔會估到GPU會off-load到一部分CPU workload?
作者: Puff 時間: 2012-4-15 22:33
引用:
原帖由 qcmadness 於 2012-4-15 22:32 發表
呢個係要解通, 因為Intel / AMD / NVIDIA都話係會向hetergeneous computing走
你可以話唔可能, 2002年你會唔會估到GPU會off-load到一部分CPU workload?
而我既問題一路都無變過,點解要將 Speedy, Narrow FPU (say 3+ Ghz) 用 GPU 取代?如果係咁,將 CPU 用 CU 取代埋唔好?一樣有 Scalar GPR 既 Scalar Unit.
作者: qcmadness 時間: 2012-4-15 22:34
引用:
原帖由 Puff 於 2012-4-15 22:33 發表
已經 offload 左啦。Graphics/3D.
而我既問題一路都無變過,點解要將 Speedy, Narrow FPU (say 3+ Ghz) 用 GPU 取代?如果係咁,將 CPU 用 CU 取代埋唔好?一樣有 Scalar GPR 既 Scalar Unit. ...
作者: Puff 時間: 2012-4-15 22:37
引用:
原帖由 qcmadness 於 2012-4-15 22:34 發表
如果你用CU取代CPU, 一粒Tahiti會變左1000mm^2+, 因為x86 rigid同restricted好多
[ 本帖最後由 Puff 於 2012-4-15 22:38 編輯 ]
作者: qcmadness 時間: 2012-4-15 22:37
引用:
原帖由 Puff 於 2012-4-15 22:37 發表
關 Tahiti 乜事?然後重點問題依然未答。Why should AMD replace the fast, narrow 4-wide FPU within the CPU with a slow, flat 32-wide GPU?
一係雙方都改, 之後merge (AMD)
一係CPU用GPU方法設計 (NVIDIA)
一係GPU用CPU方法設計 (Intel)
作者: Puff 時間: 2012-4-15 22:39
引用:
原帖由 qcmadness 於 2012-4-15 22:37 發表
因為要盡用GPU的FP power
作者: qcmadness 時間: 2012-4-15 22:40
引用:
原帖由 Puff 於 2012-4-15 22:39 發表
Goddess. 我真心想問呢兩者關乜事。
作者: Puff 時間: 2012-4-15 22:40
然後我從頭到尾都唔明點解唔可以有 software interception. Multi-core 都要有 software interception 啦。
作者: qcmadness 時間: 2012-4-15 22:41
引用:
原帖由 Puff 於 2012-4-15 22:40 發表
然後我從頭到尾都唔明點解唔可以有 software interception. Multi-core 都要有 software interception 啦。
hardware做到幫你揀埋, 咪唔駛咁難咁tune個complier
作者: Puff 時間: 2012-4-15 22:41
引用:
原帖由 qcmadness 於 2012-4-15 22:40 發表
無共同語言, 就唔會多人用, 呢樣野好現實的
點解要 asm 一樣?asm 係 for low-level optimization 咋喎。而且呢個世界有 LLVM 啦。
作者: qcmadness 時間: 2012-4-15 22:42
引用:
原帖由 Puff 於 2012-4-15 22:41 發表
現實只要有 easy to use & efficient 既 software development stack 同 it's worth 就得。
點解要 asm 一樣?asm 係 for low-level optimization 咋喎。而且呢個世界有 LLVM 啦。
...
就算Intel都攪唔掂 (GPU part)
你天真地以為AMD做到?
NVIDIA都一樣辛苦
作者: Puff 時間: 2012-4-15 22:42
引用:
原帖由 qcmadness 於 2012-4-15 22:41 發表
我指既係external ISA, 你而家係指定要用邊個先用邊個, 要software揀定用邊個
hardware做到幫你揀埋, 咪唔駛咁難咁tune個complier
作者: Puff 時間: 2012-4-15 22:42
引用:
原帖由 qcmadness 於 2012-4-15 22:42 發表
AMD唔會咁既resource
HSA.
作者: qcmadness 時間: 2012-4-15 22:43
引用:
原帖由 Puff 於 2012-4-15 22:42 發表
但佢地就係做緊。
HSA.
作者: Puff 時間: 2012-4-15 22:44
引用:
原帖由 qcmadness 於 2012-4-15 22:43 發表
certainly a failure
作者: Puff 時間: 2012-4-15 22:48
引用:
原帖由 qcmadness 於 2012-4-15 22:42 發表
就算Intel都攪唔掂 (GPU part)
你天真地以為AMD做到?
NVIDIA都一樣辛苦
Intel 自己搞 Graphics Pipeline on Many CPU cores with only texture unit 係佢自己既事,搞 Graphics 無 Graphics Fixed-function Unit 所以先 epic fail。至於 Heterogeneous Computing... Intel 根本都未推過普及產品,得 Ivy Bridge 先叫開始普及 (OpenCL support)。同 AMD 要做既野無衝突。得 Nvidia 係同 AMD 一樣走緊相近既路。
作者: Henry 時間: 2012-4-15 23:01
引用:
原帖由 Puff 於 2012-4-15 22:40 發表
然後我從頭到尾都唔明點解唔可以有 software interception. Multi-core 都要有 software interception 啦。

作者: qcmadness 時間: 2012-4-15 23:05
引用:
原帖由 Henry 於 2012-4-15 23:01 發表
我想知有無人而家寫Program會睇Assembly code甚至Machine code,有無計過CPU/GPU每個需時幾耐,有幾多Overhead,應該點樣配合之類?
作者: Henry 時間: 2012-4-15 23:06
引用:
原帖由 Puff 於 2012-4-15 22:48 發表
我覺得係又係兩回事。
Intel 自己搞 Graphics Pipeline on Many CPU cores with only texture unit 係佢自己既事,搞 Graphics 無 Graphics Fixed-function Unit 所以先 epic fail。至於 Heterogeneous Computing... ...
AMD個CPU部門唔夠Intel鬥,要避重就輕,另覓路徑.
不過GPU係咪真係可以取代CPU?:shakehand
CPU: 低量複雜工作
GPU: 大量簡單工作
當然最後都想做到一個架構係可以處理到大量複雜工作既時候,GPU係咪真係有全部優勢?
| 歡迎光臨 HKSpot (https://bbs.hk-spot.com/) |
Powered by Discuz! 6.0 Lite |
