引用:
原帖由 qcmadness 於 2012-5-1 23:05 發表
IvyBridge core + L1 / L2: 17.4mm^2 (22nm)
Bulldozer module + L1 / L2: 30.9mm^2 (32nm)
原帖由 qcmadness 於 2012-5-1 23:05 發表
IvyBridge core + L1 / L2: 17.4mm^2 (22nm)
Bulldozer module + L1 / L2: 30.9mm^2 (32nm)


原帖由 qcmadness 於 2012-5-2 00:27 發表
update左
原帖由 cheungmanhoi 於 2012-5-2 10:11 發表
反而想知 肥2果d一個core幾多mm^2?
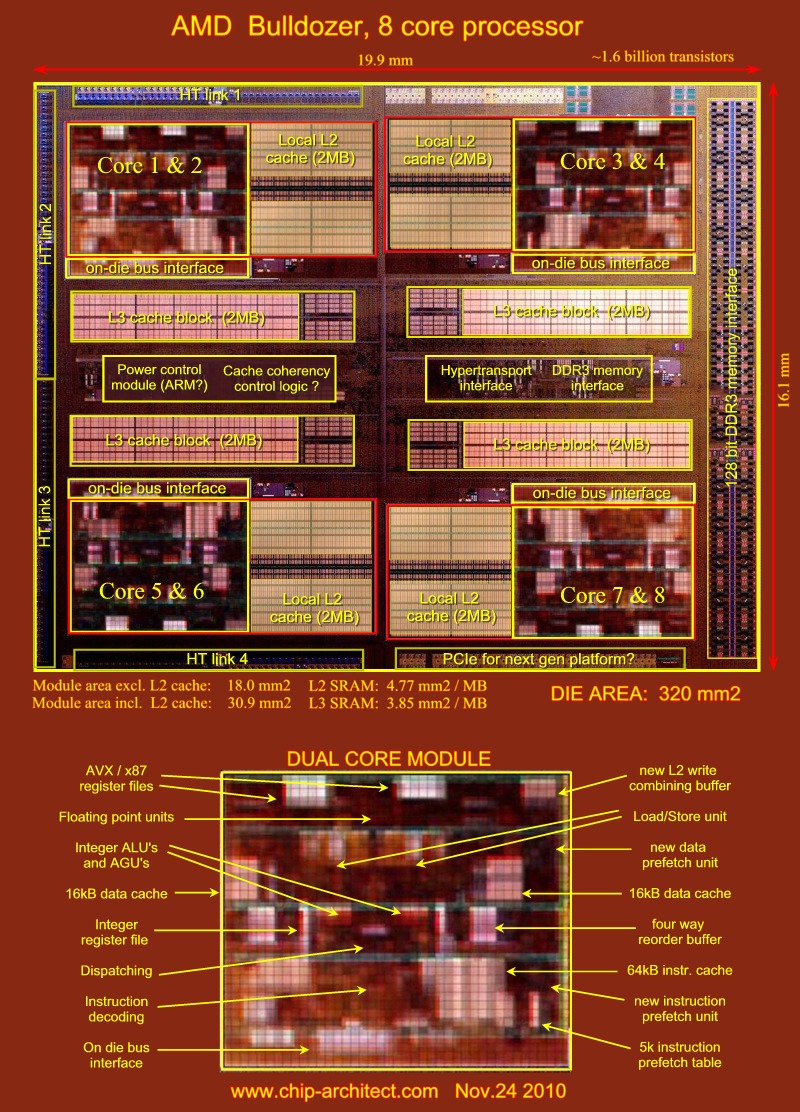


原帖由 qcmadness 於 2012-5-3 23:59 發表
L2 cache size太大
但係主要係因為cache miss太多

原帖由 Puff 於 2012-5-4 20:59 發表
L1 cache miss...
原帖由 qcmadness 於 2012-5-4 21:00 發表
L1同L2都多
原帖由 Puff 於 2012-5-4 21:02 發表
點介定係「多」?無 processor 唔會無 cache miss 掛。
比起 Small L2,Hit rate 應該更高喎。除非你講緊 large dataset 下 mispredict 既綜合副作用姐。
原帖由 dom 於 2012-5-5 01:04 發表
1. AMD need to improve ther prefetching .......
2. L3 ....slow , when will they finally FIX IT UP ?
原帖由 qcmadness 於 2012/5/5 01:06 發表
you will faint if you know the l1 speed
原帖由 dom 於 2012-5-5 01:13 發表
FX-4100 latency 67.x ns ... (DDR3-1600 CL9)
Phenom II X6 1045T latency 64.5ns (DDR3-1600 CL9)
原帖由 qcmadness 於 2012/5/5 01:33 發表
I mean L1 cache latency

原帖由 dom 於 2012-5-5 01:07 發表
32nm Gen2 Product (Trinity / Piledriver ) 希望好睇d , 執翻 Faildozer Module 個 front-end 正常

原帖由 XT 於 2012-5-5 02:20 發表
AMD 長久以來都處理唔到個latency問題
| 歡迎光臨 HKSpot (https://bbs.hk-spot.com/) | Powered by Discuz! 6.0 Lite |

